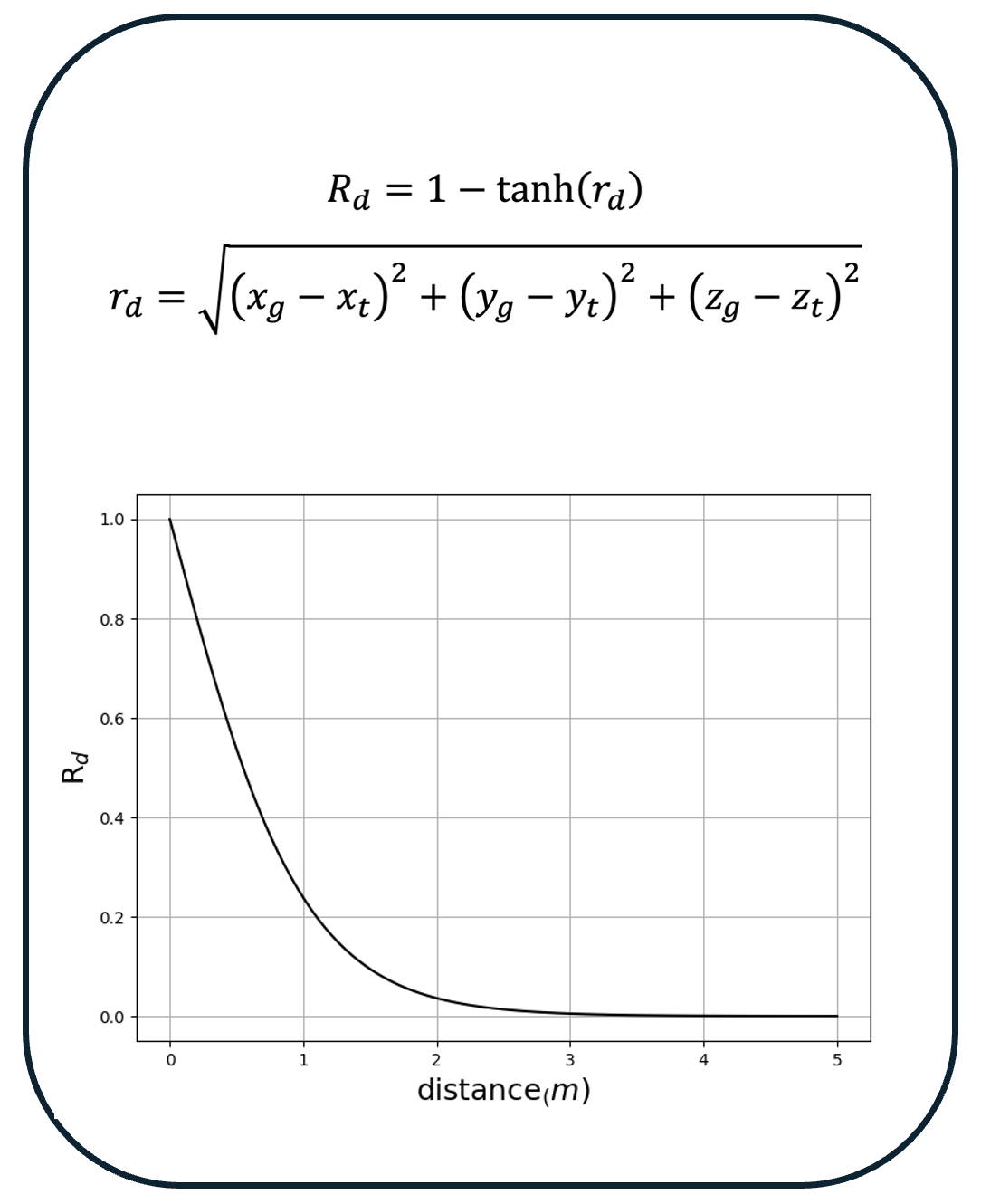
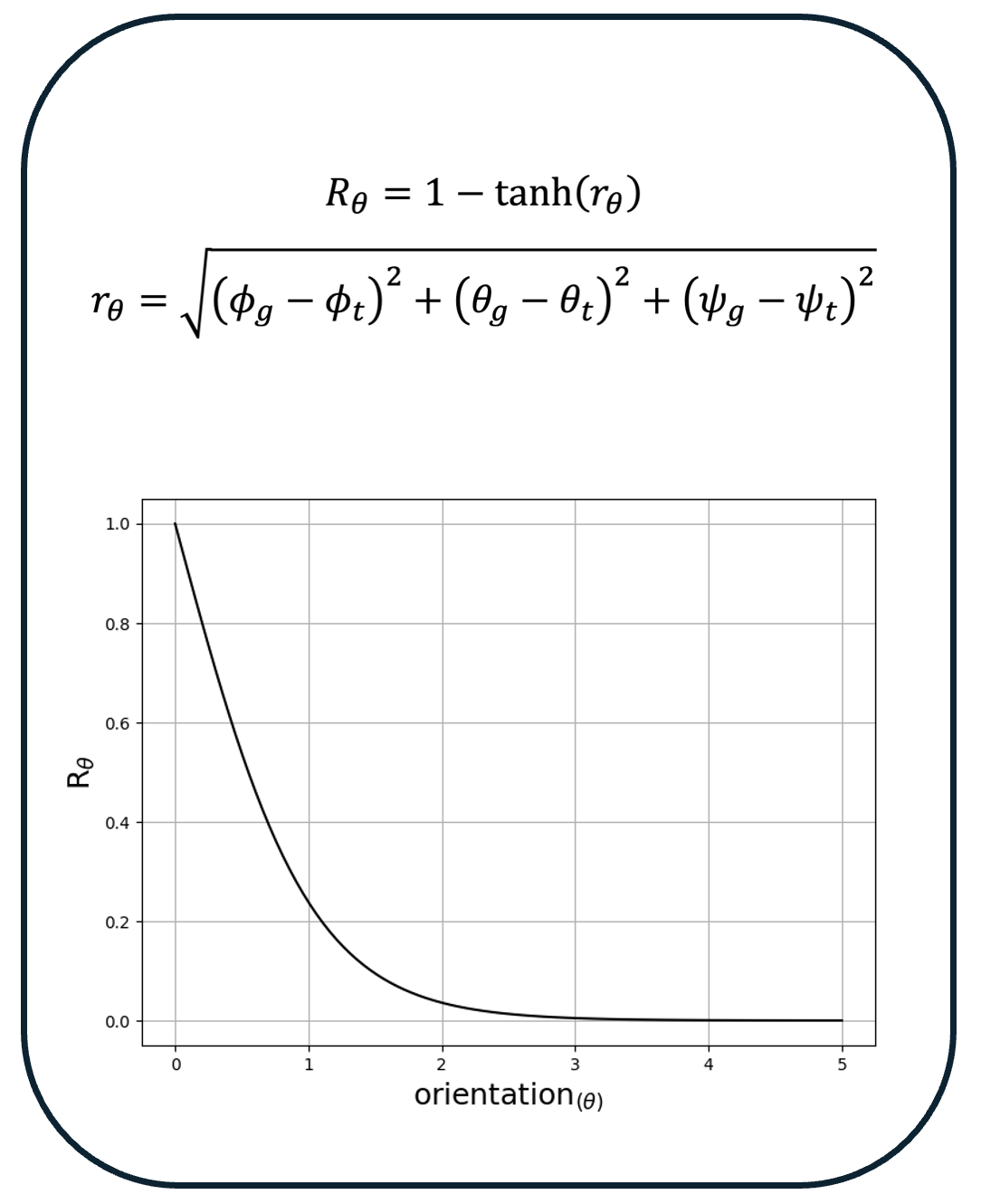
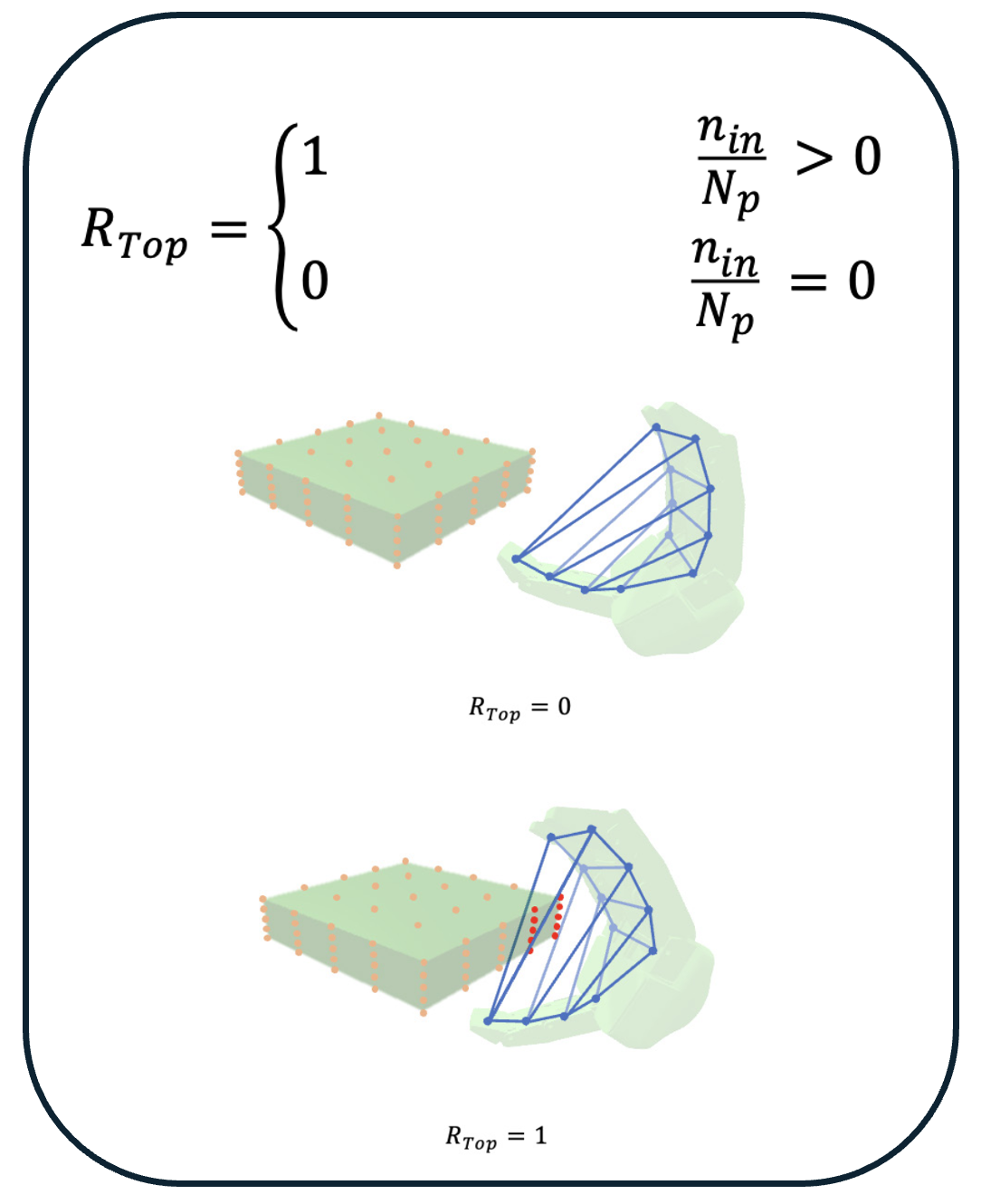
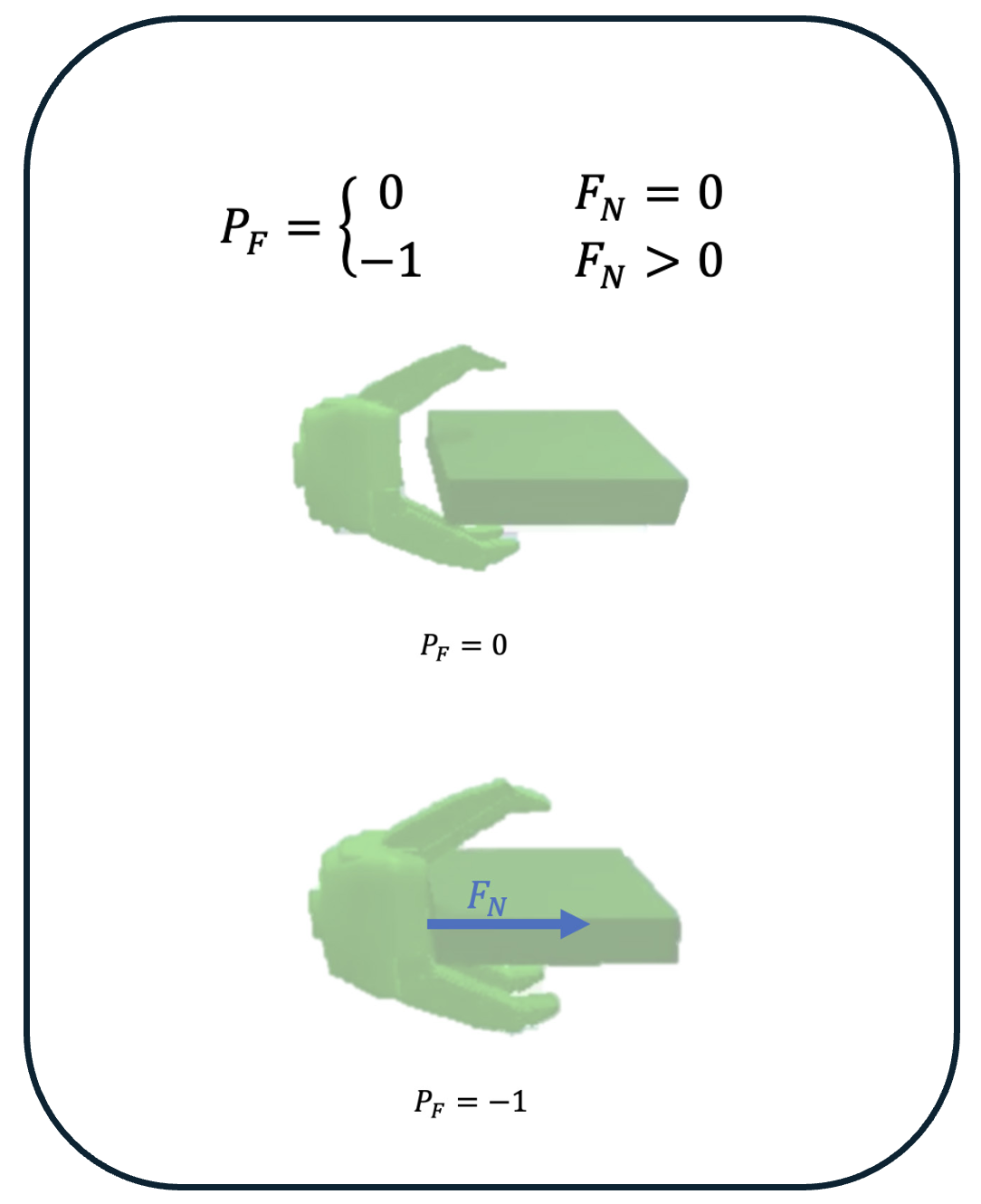
Pre-positioning a robotic gripper relative to a free-floating, moving target in 6-DoF poses significant challenges, especially when both translation and rotation are involved.
Precise pre-positioning is critical for successful grasping, as deviations from the optimal pose may result in missed grasp opportunities or collisions.
This work addresses these challenges by leveraging reinforcement learning with curriculum learning to enhance both the efficiency and adaptability of the robotic agent in dynamic environments.
Curriculum learning is used to incrementally increase task complexity, enabling the agent to adapt to unforeseen conditions while maintaining precise control.
The proposed approach uses a Soft Actor-Critic algorithm with deterministic policy output, first trained in the PyBullet simulation environment with domain randomization to mitigate sim-to-real transfer issues.
The trained policy is then transferred to a physical robot to perform dynamic pre-positioning tasks.
Our results demonstrate that this method enables the robotic gripper to accurately track and maintain the correct pose relative to a 6-DoF moving and rotating target, ensuring collision-free pre-positioning, a crucial precursor to grasping.
More detailed results and videos are available at GitHub.