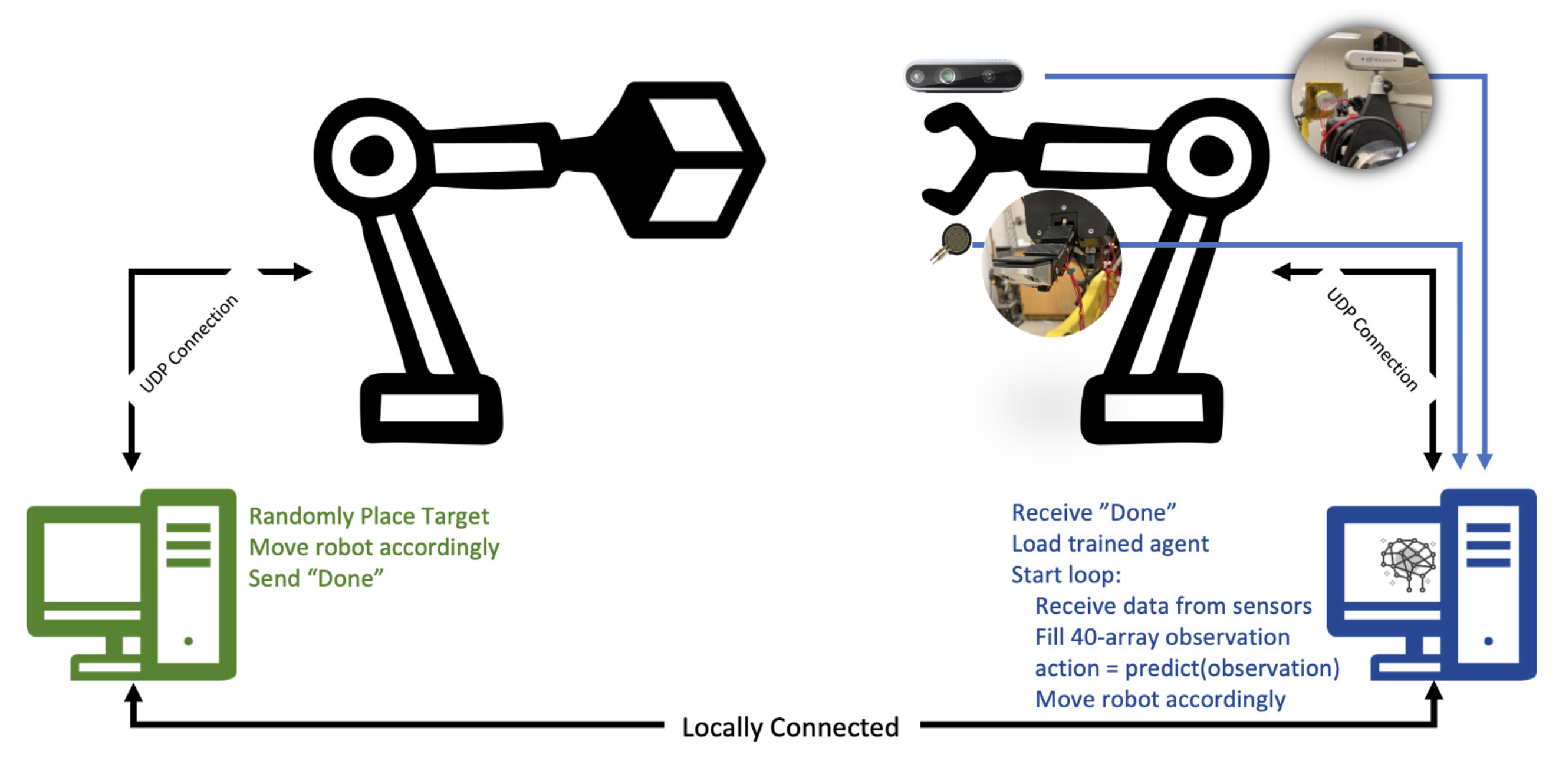
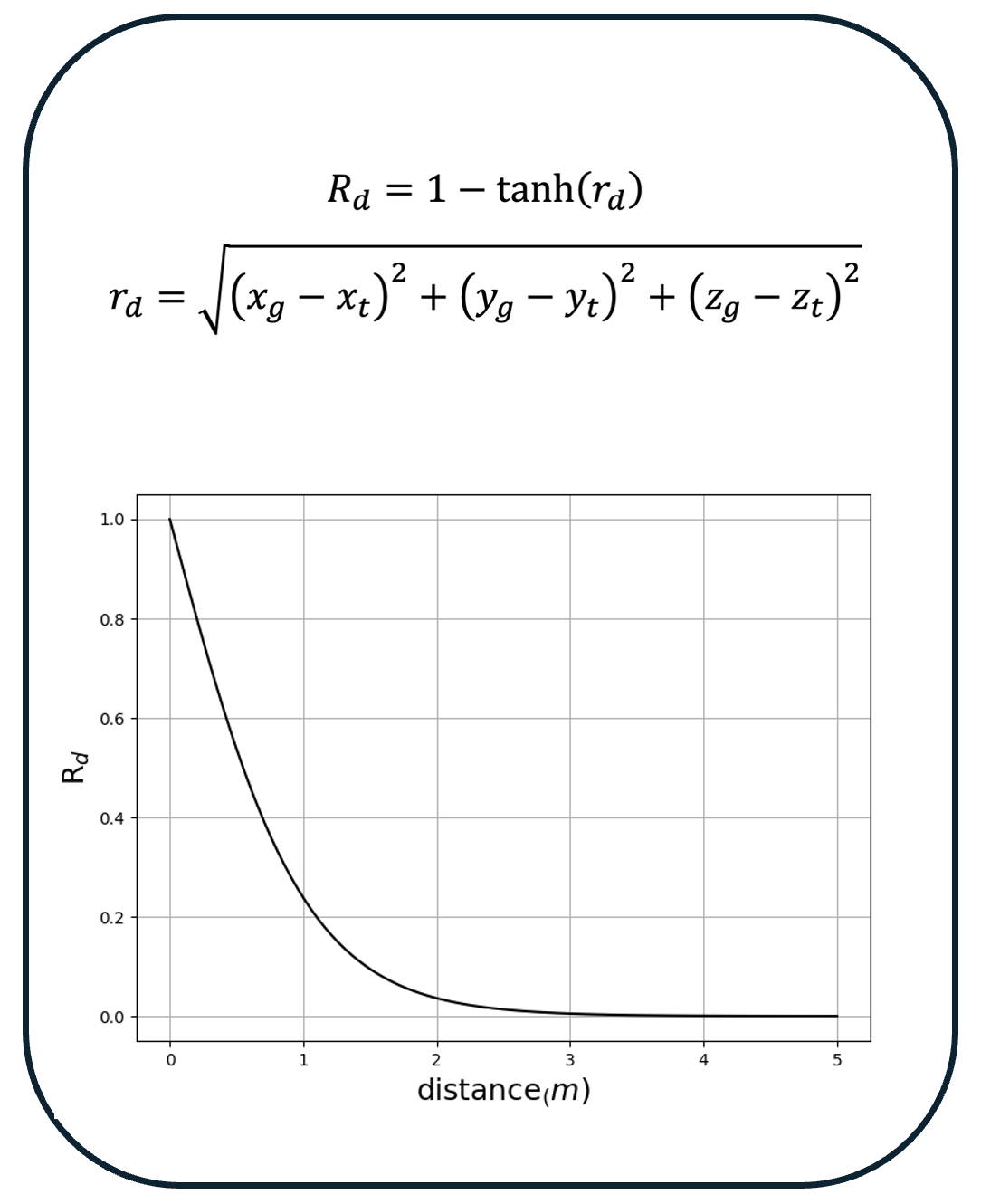
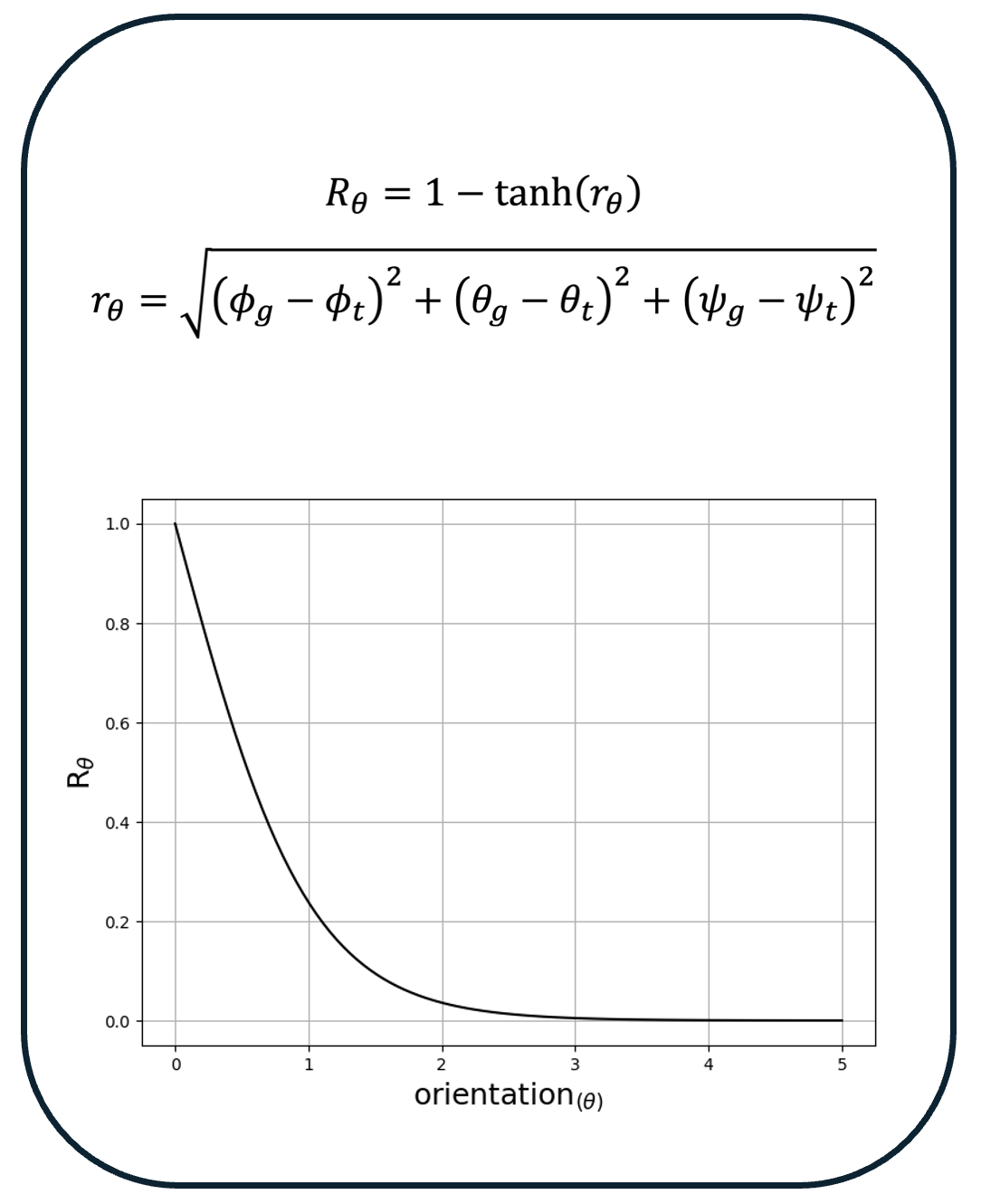
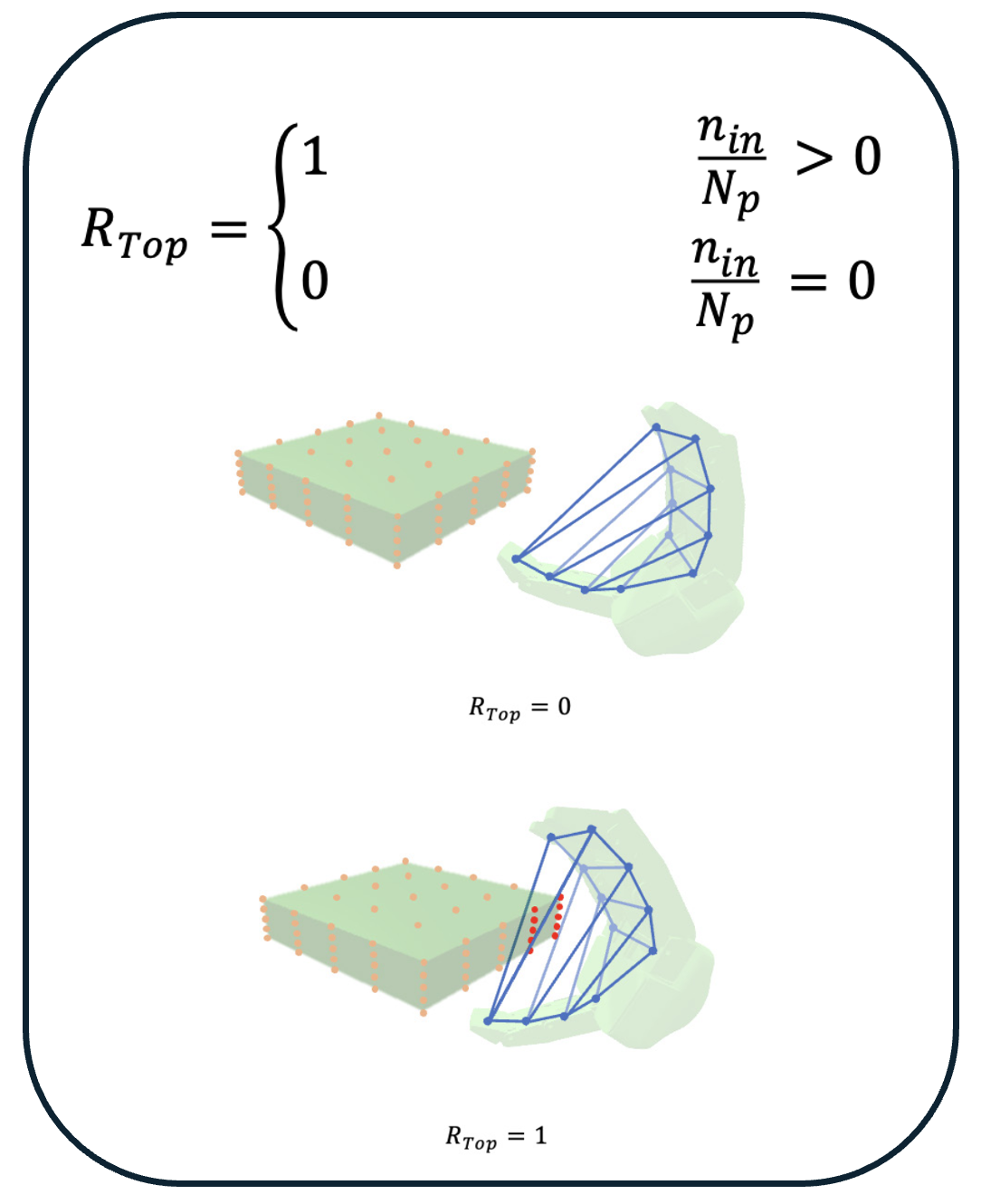
In this research, we introduce a deep reinforcement learning-based control approach to address the intricate challenge of the robotic pre-grasping
phase under microgravity conditions. Leveraging reinforcement learning eliminates the necessity for manual feature design, therefore simplifying
the problem and empowering the robot to learn pre-grasping policies through trial and error.
Our methodology incorporates an off-policy
reinforcement learning framework, employing the soft actor-critic technique to enable the gripper to proficiently approach a free-floating
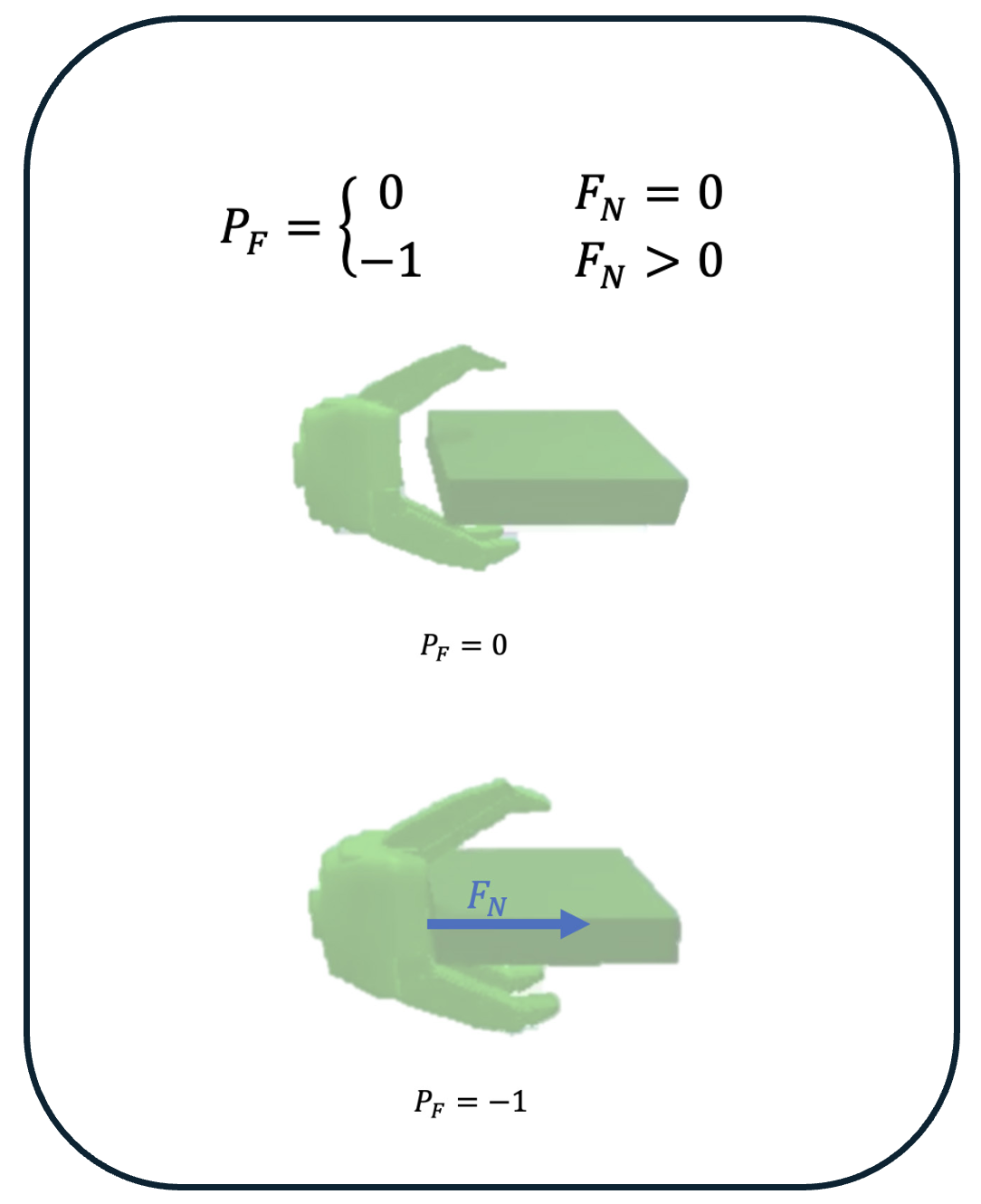
moving object, ensuring optimal pre-grasp success. For effective learning of the pre-grasping approach task, we developed a reward function that
offers the agent clear and insightful feedback. Our case study examines a pre-grasping task where a Robotiq 3F gripper is required to navigate
towards a free-floating moving target, pursue it, and subsequently position itself at the desired pre-grasp location.
We assessed our approach
through a series of experiments in both simulated and real-world environments.